
Background:
Deep reinforcement learning (DRL) methods such as the Deep Q-Network (DQN) have achieved state-of-the-art results in a variety of challenging, high-dimensional domains.
One of the major problems in DRL is that the state and action spaces are large, and the task often becomes an exploration problem.
While DRL methods are new, RL is a well established field. There exist various algorithms in the tabular case which ensure proper exploration and convergence to the optimal solution. Such an algorithm is the Model-free AE Algorithm as proposed by Even-Dar et.al. (page 1095).
Recently Bellemare et.al. have proposed an improvement. Their method uses pseudo-counts to give additional intrinsic motivation for the agent to explore better.
In our project we used the pseudo-counts method proposed by Bellemare et.al, and implemented the ‘Model-free AE Algorithm’ as a robust exploratory solution.
Abstract:
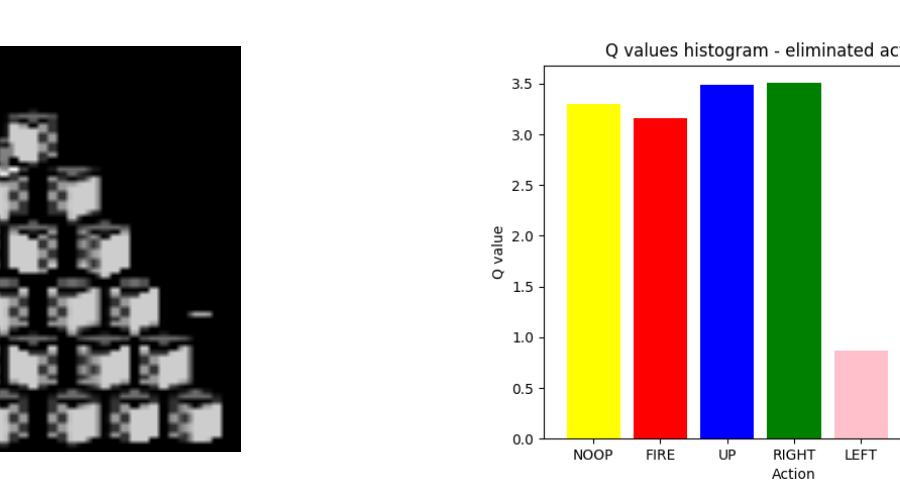
We consider an environment with a low error margin for an agent. Specifically, we focus on the problem of exploration in a hostile environment where some of the actions will lead to poor results and the certain death of the agent. Drawing inspiration from model-free variants of the elimination method (Even-Dar, Manor, and Mansour, 2006) which maintains an upper and lower confidence bound for the Q values. We transfer a probabilistic approach that has confidence intervals to bound the values of the Q network, into a deep learning method.
With this technique, we aim to identify “bad actions” and eliminate them from the agent’s action pool. We test our framework approach on Atari 2600 games (specifically Qbert) and try to outperform the vanilla DQN implementation in environments where some of the actions lead to the certain death of the agent.