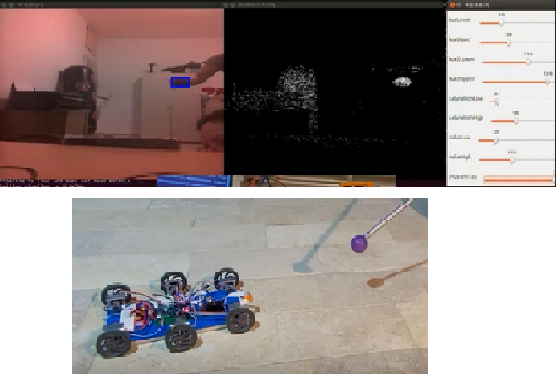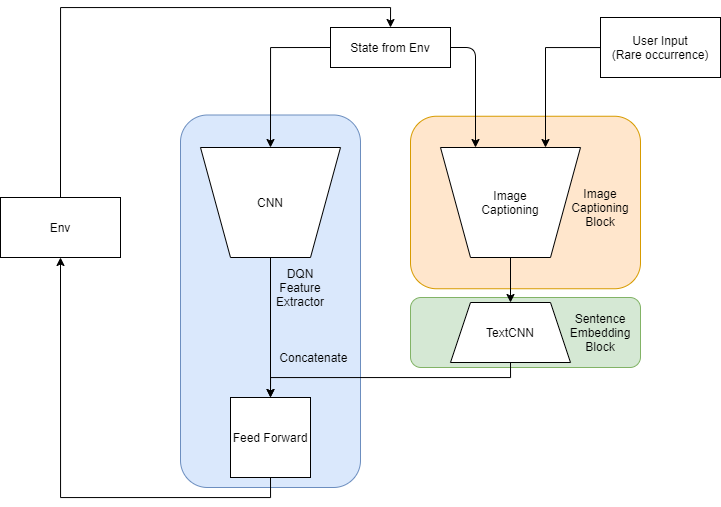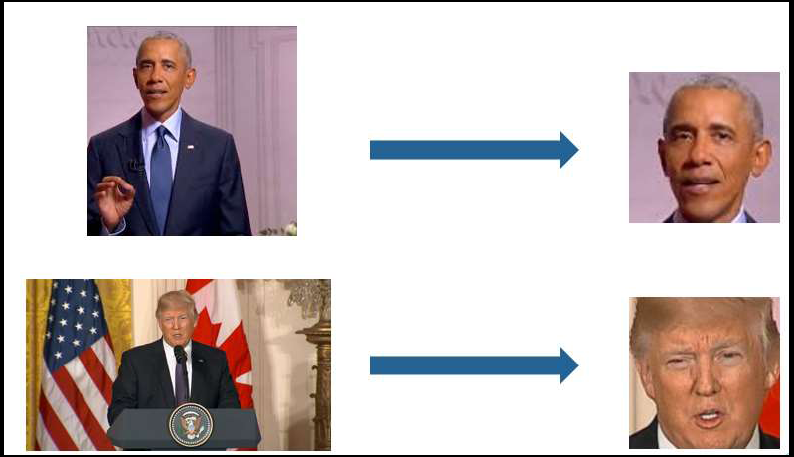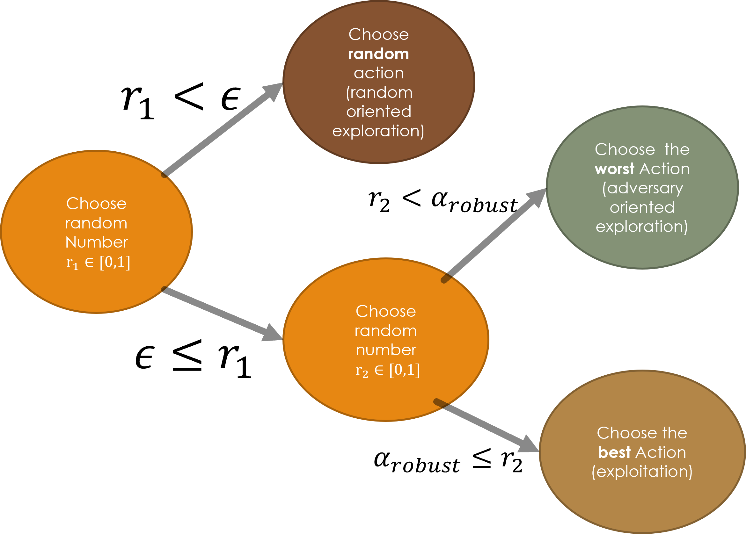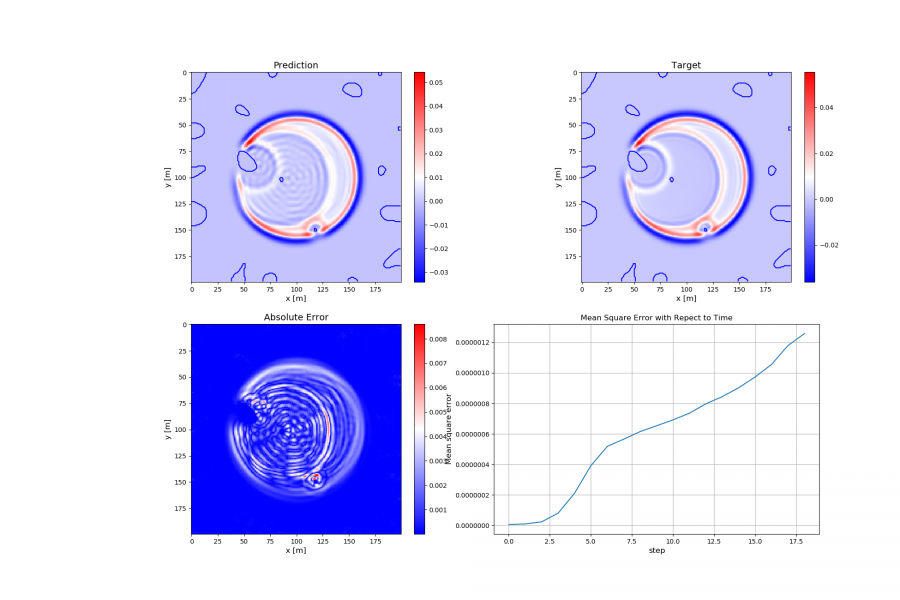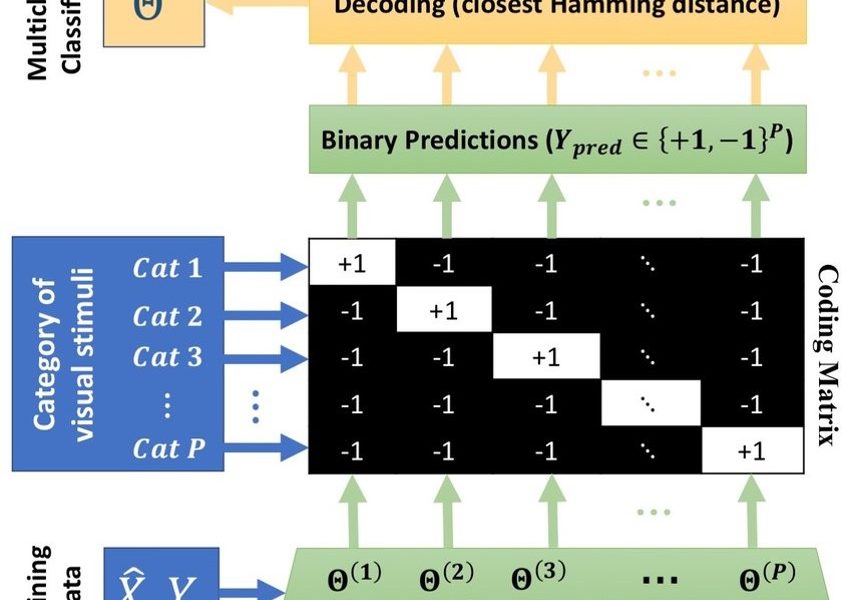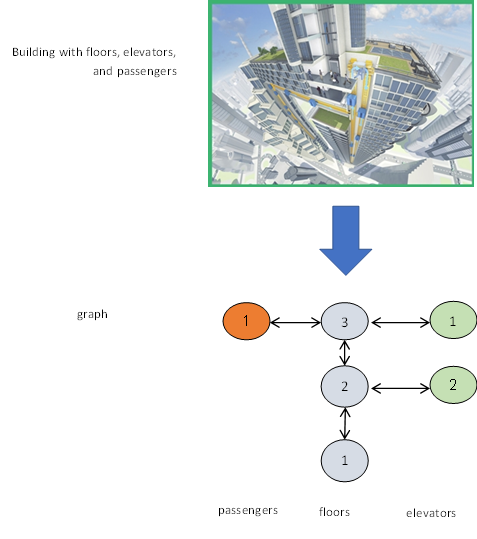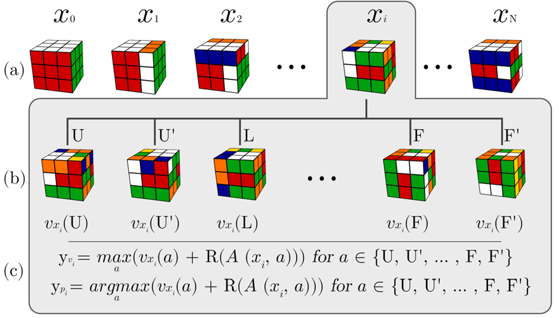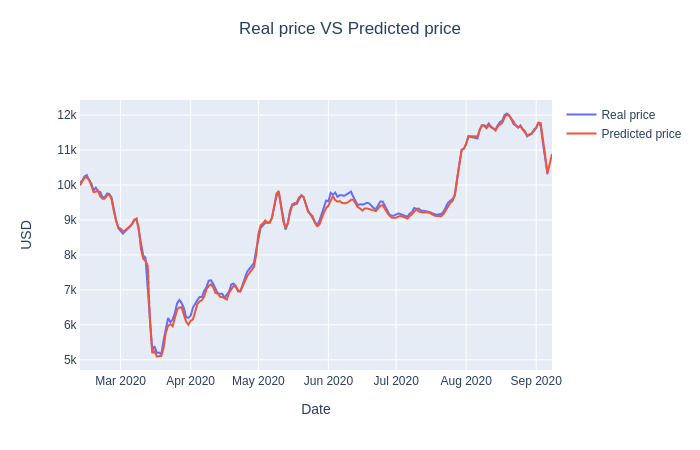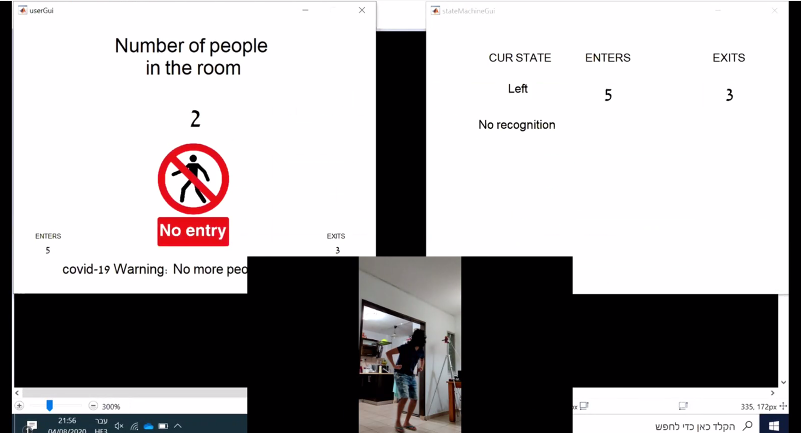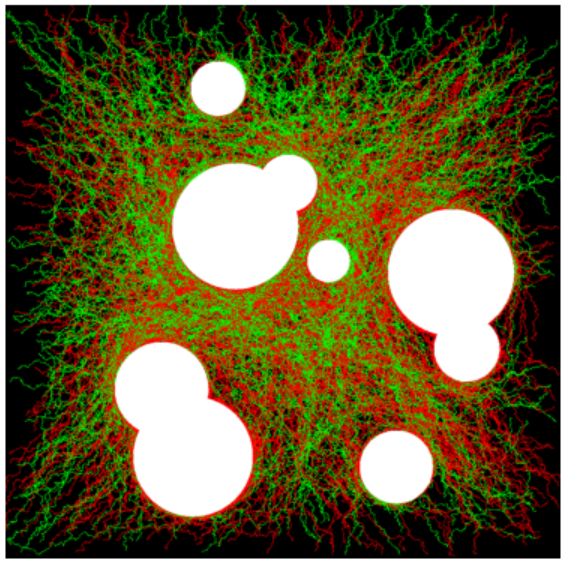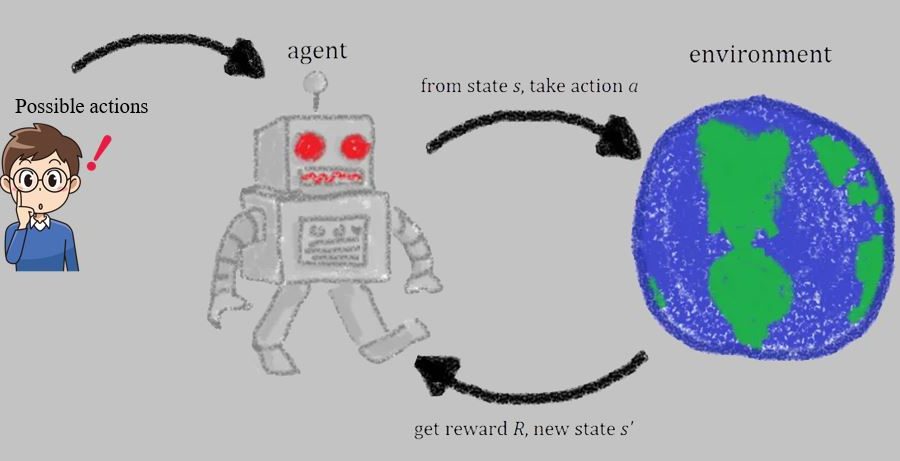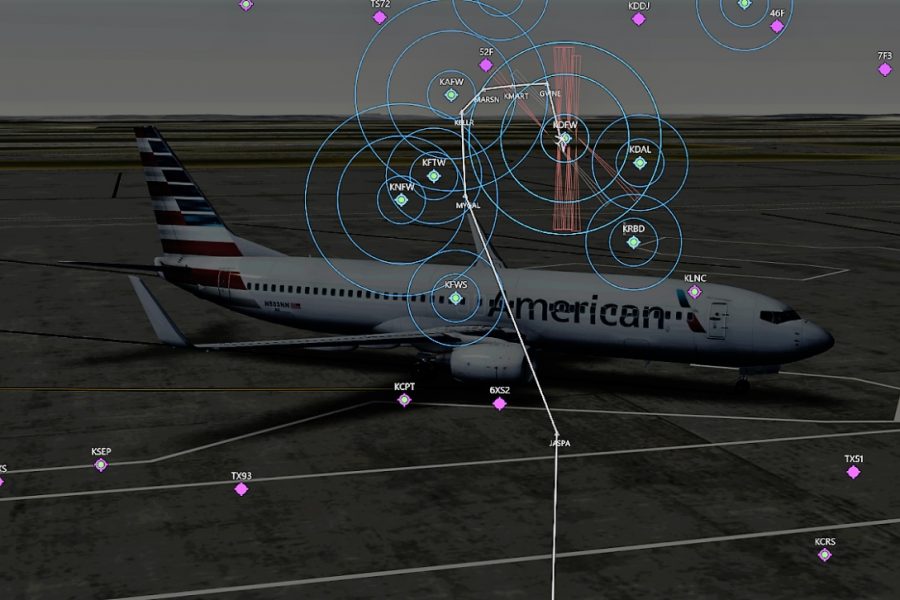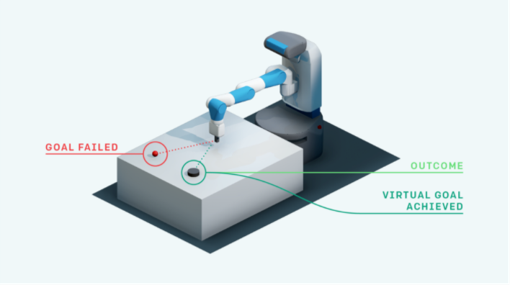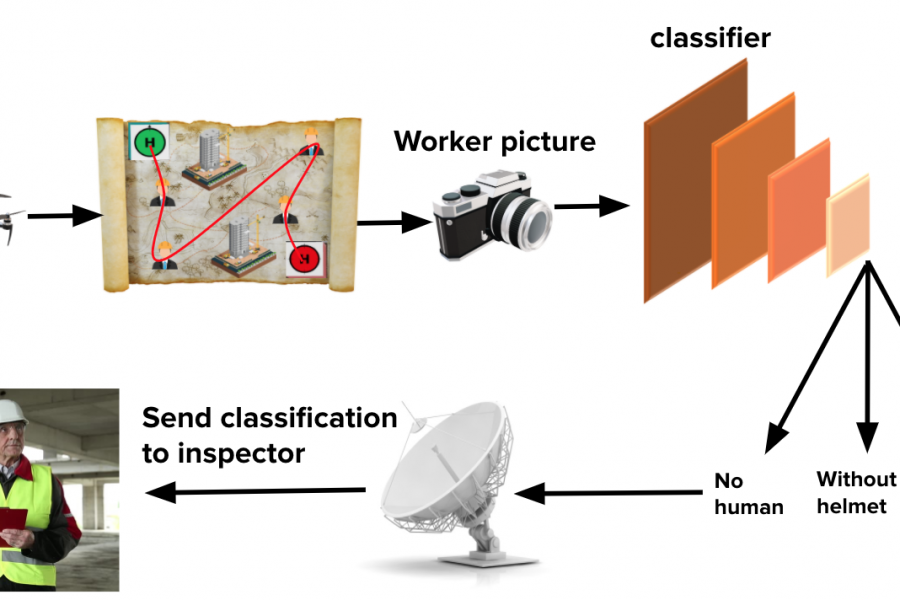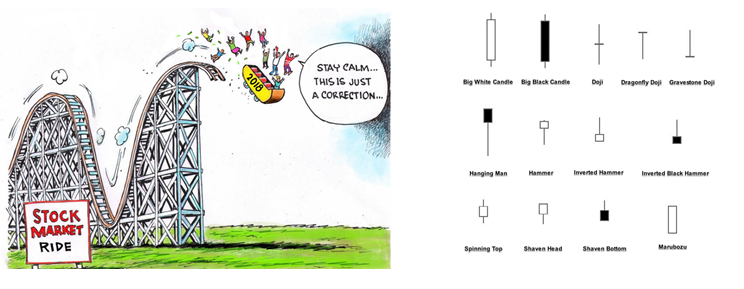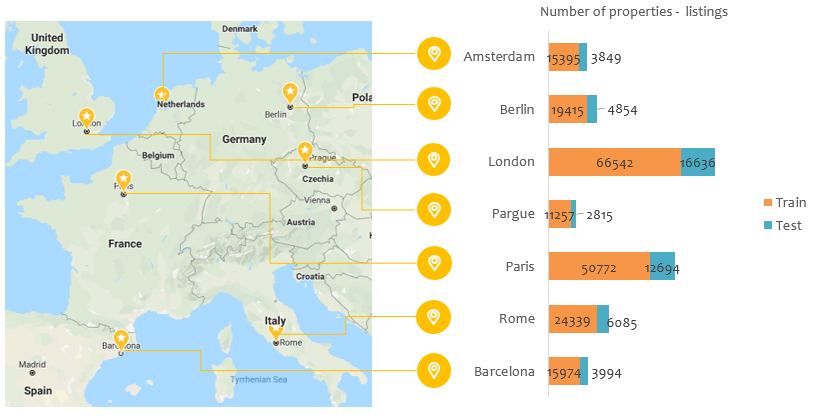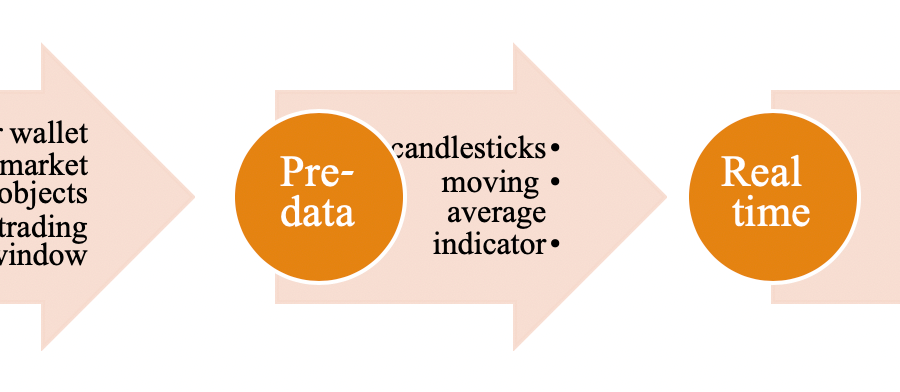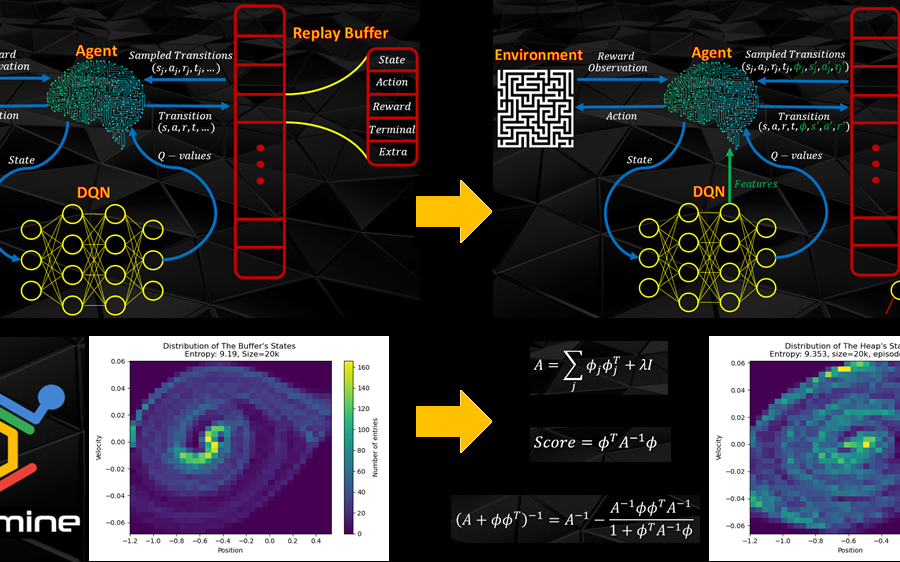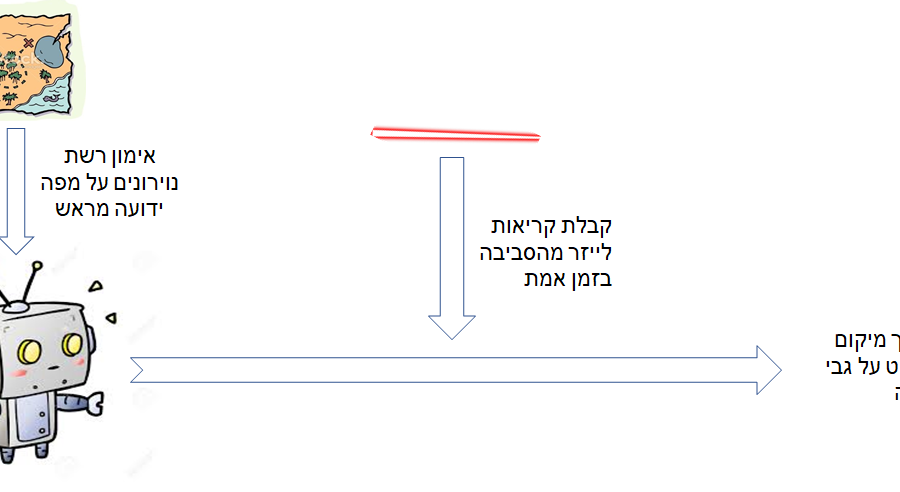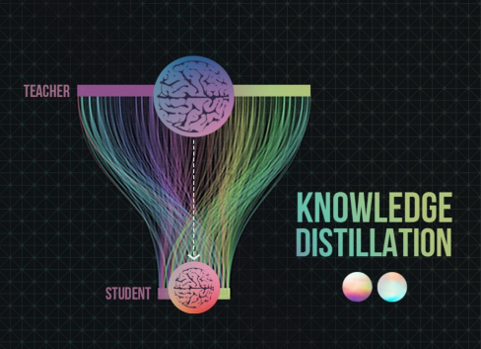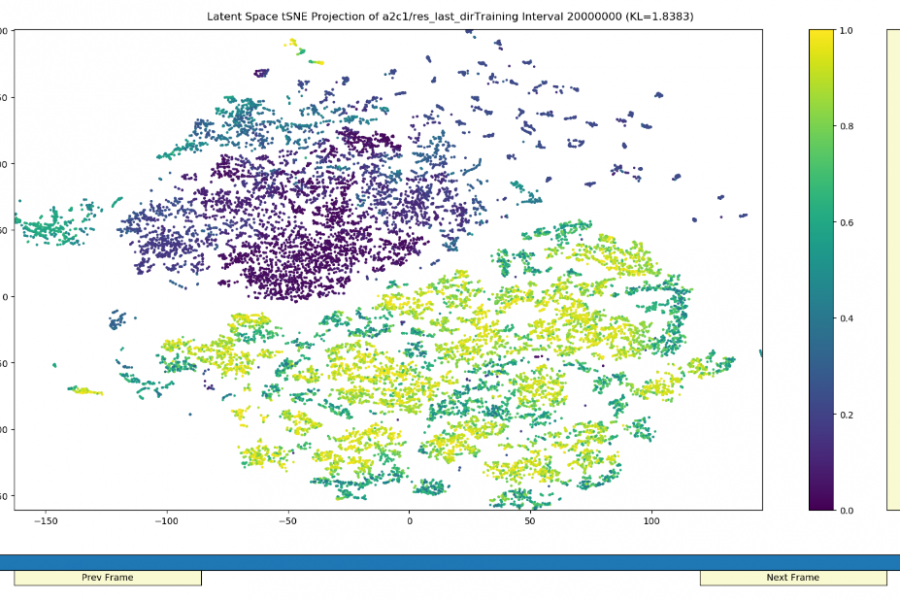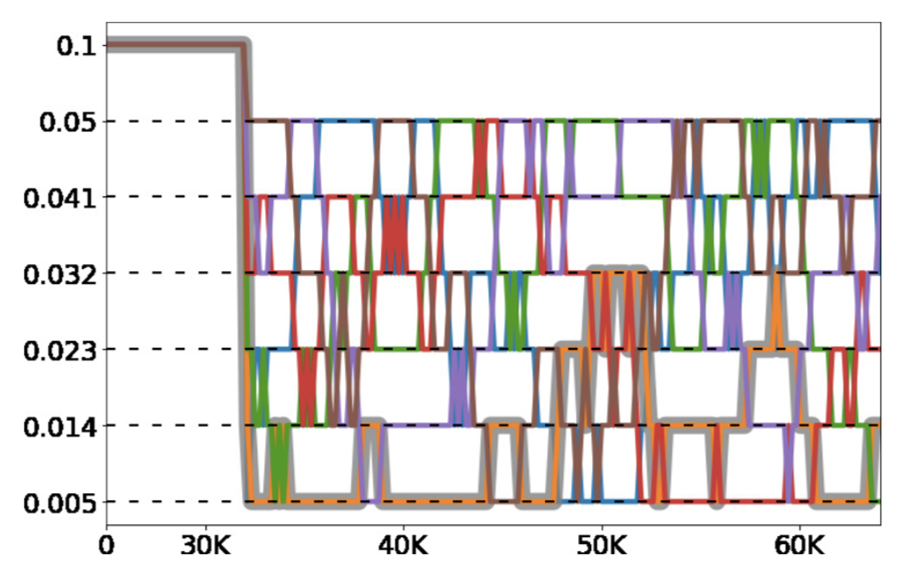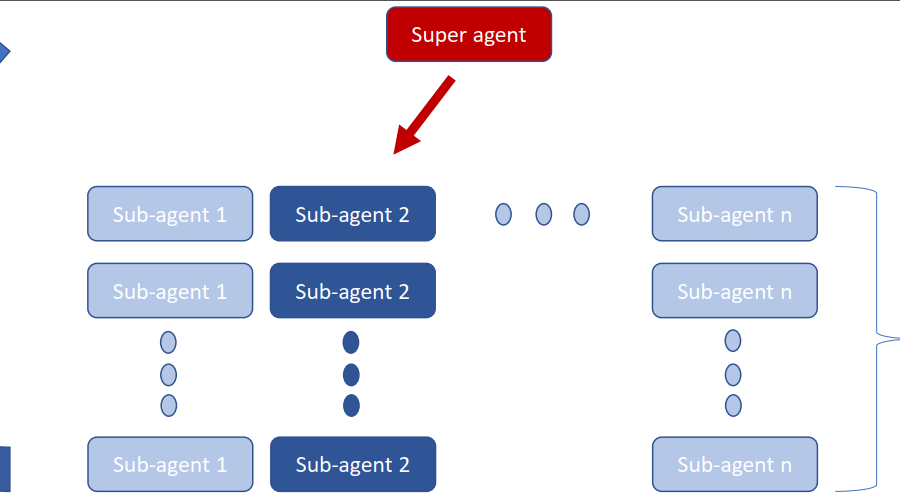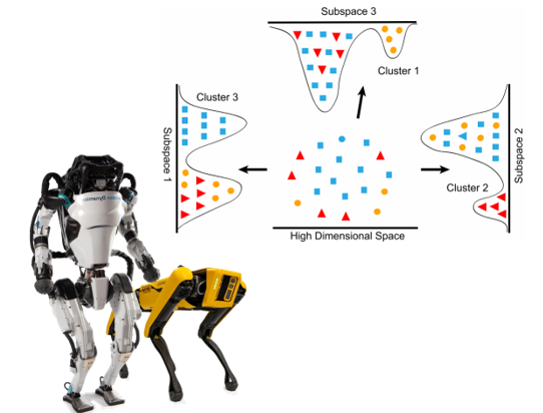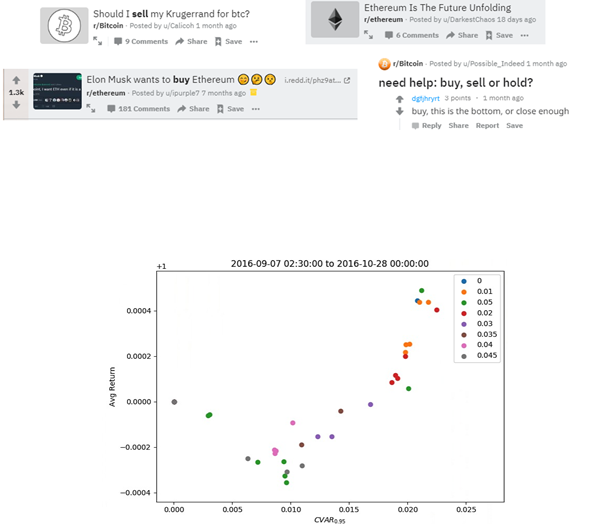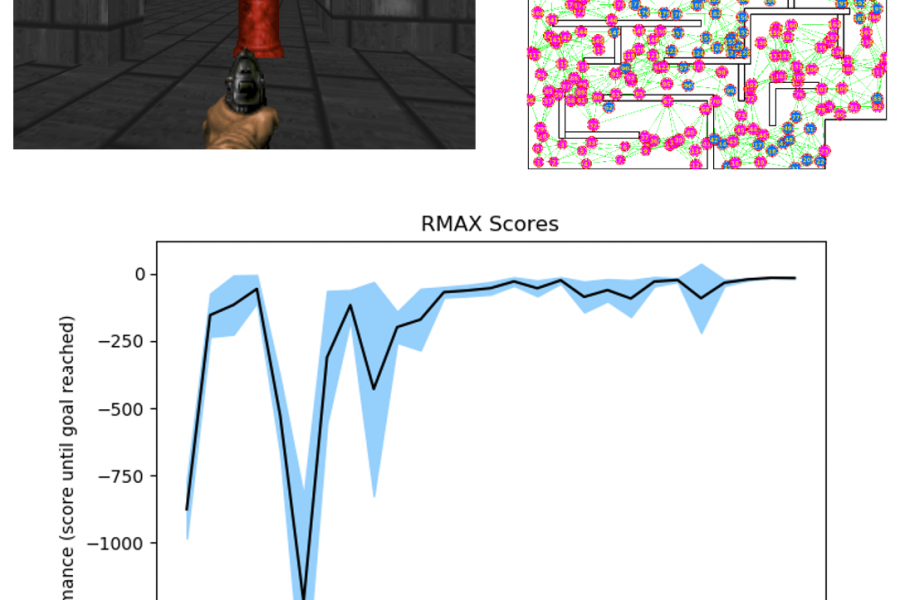
Deep Learning is part of abroader family of machine learning methods based on artificial neural networks with representation learning. Deep learning architectures such as convolutional neural networks have been applied to fields including computer vision, machine vision, board games and much more, where they have produced results comparable to and in some cases surpassing human expert performance. In deep learning, a convolutional neural network(CNN, or ConvNet) is a class of...
Categories:
Machine Learning