
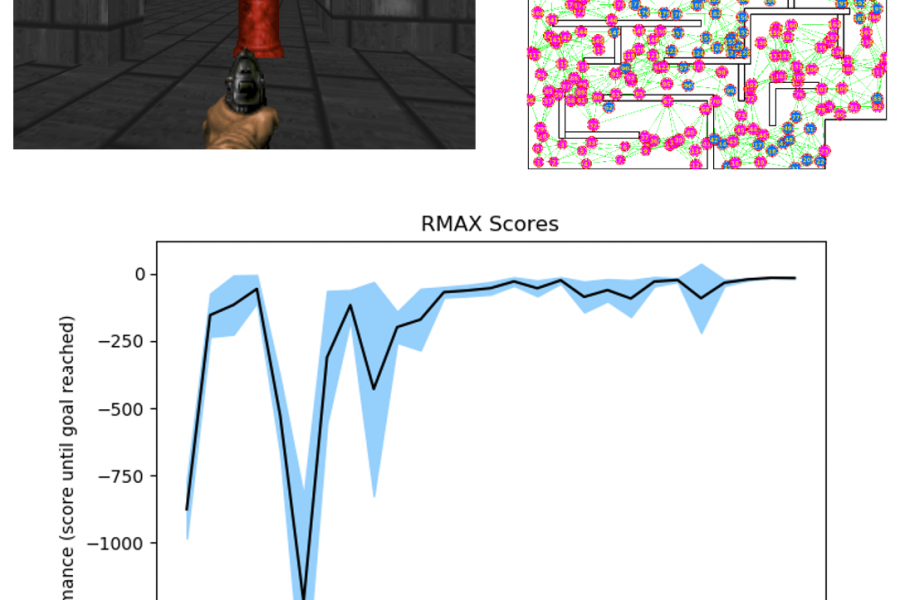
We address the problem of solving high dimensional MDPs using its minimization by sampling and solving a navigation problem on a graph using RMAX. Many previous attempts optimize the policy using deep models with some success but lack the theoretical guaranties. Our methods provide a framework to incorporate classical reinforcement learning algorithms which provide guaranties. Moreover, the method can be extended using deep models to solve more specific problems. The experiments are done in the VizDoom 3D environment simulation.