
Accurately predicting memory consumption before running code can significantly reduce resources costs and prevent crashes, especially in large-scale or resource-constrained environments.
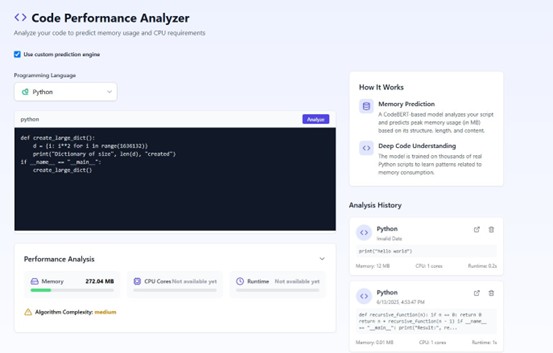
This project focuses on predicting memory consumption of Python code using large language models (LLMs), particularly CodeBERT. Traditional methods for estimating resource usage struggle to generalize across diverse code patterns and often rely on handcrafted features. In contrast, this project leverages the deep contextual understanding of LLMs, treating code as natural language and fine-tuning CodeBERT for regression. The model was trained on a generated and uniformly distributed dataset to enhance generalization across a wide memory usage spectrum. The training pipeline included tokenization, z-score normalization, and model evaluation using metrics like R², MAE, and RMSE. Initial results showed high accuracy on familiar distributions but limited generalization, motivating further architectural improvements.
To overcome these limitations, we introduced an improved model architecture using a multi-head attention, specialized numerical and semantic feature extractors, and a deep regression head with skip connections. Numerical tokenization challenges were addressed with a log-based preprocessing pipeline, and model optimization was guided by Optuna’s Bayesian hyperparameter search. The final model achieved a R² of 0.868 with an average absolute error of 496KB, demonstrating strong performance and generalization. To support practical use, a full web-based GUI was developed, providing an accessible platform for code analysis and memory prediction. This project demonstrates how advanced NLP techniques can be effectively adapted to solve low-level performance challenges in software engineering.