Transfer Learning in the field of machine learning is the method of using knowledge gained while learning previous tasks on a new task. In Reinforcement Learning, one way to utilize Transfer Learning is using the knowledge gained while training an agent in a specific domain on a task with its respective reward function, on a new task in the same domain but with different reward function.
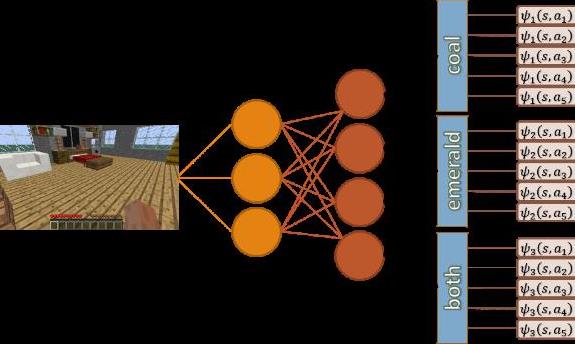
Barreto et al. (2017) came up with an implementation of a method called Successor Features (SF) that allows us to decouple the dynamics of the domain from the reward function that define our task: Suppose that the expected reward associated with transition (s; a; s') can be computed as inner product of d features with vector of weights.
Then, if we call the features phi, we can define psi as the expected discounted sum of phi following our policy (exactly as we define the Q function w.r.t the reward) and we will get that the equation of psi will follow the Bellman Equation.
In this paper we present our combination of the Successor Features ideas with the Deep Q Network algorithm (DQN) to create the Successor Features Deep Q Network (SFDQN).
Our experiments, performed on Minecraft environment using Malmö framework, shows that SFDQN enables efficient transfer learning of knowledge and multitask learning on different tasks at the same domain.