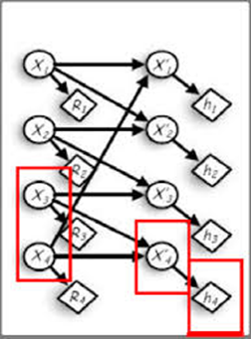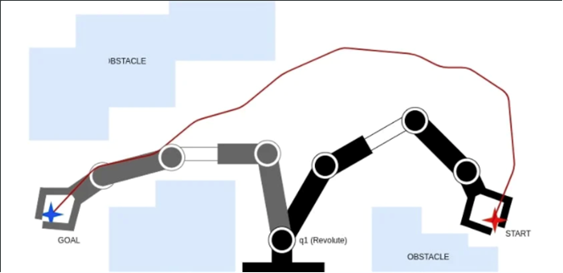
MuZero is a recent reinforcement learning (RL) algorithm that learns how to plan by combining ideas from the planning and the RL communities. In this project we would like to investigate: how well can MuZero solve the motion planning problem? In the motion planning problem a robot needs to navigate between a start position to a goal position without colliding with obstacles along the way. This problem is particularly difficult...
Categories:
Machine Learning